


北京基因組研究所(國家生物信息中心)合作發布大豆多維組學數據庫SoyOmics
大豆(Glycine max (L.) Merr.)作為世界范圍內重要的糧油作物之一,其產量提升、品質改進關乎全球人口的需求和利益。高通量測序技術的發展促使大豆組學研究不斷深入。實現大豆多維組學數據的整合分析,將會為大豆遺傳育種提供有力支持。
近日,中科院遺傳發育所田志喜團隊聯合中科院北京基因組所(國家生物信息中心)章張、宋述慧團隊開發了大豆多維組學深度整合數據庫SoyOmics。研究成果以“SoyOmics: A deeply integrated database on soybean multi-omics”為題在國際期刊Molecular Plant上發表。
SoyOmics數據庫全面整合分析了大豆相關的多維組學數據。數據庫目前收錄了27個大豆品系的從頭組裝基因組數據,并對相應基因組信息進行了全面的基因組注釋。以高質量的ZH13作為參考基因組,對2898份材料的全基因組測序數據進行了全基因組序列變異檢測,共鑒定到約3800萬條SNP/INDEL變異數據,同時為每個變異位點提供多層次注釋信息。除序列變異外,還提供了來自大豆泛基因組分析的約55萬條結構變異數據以及基于結構變異構建的圖泛基因組。數據庫還收錄了來自ZH13和Williams82兩個基因組27個組織時期的表達數據,以及其他26個品系9個組織時期的表達數據,并展示了不同品系間同源基因的差異表達。針對115個表型多年多點測定的約2.7萬條表型記錄進行了本體注釋和歸類,并將表型數據與變異數據進行關聯。除以上組學數據外,數據庫同時提供了部分種質資源的甲基化測序數據,以及Soy40K大豆芯片數據。該數據庫從基因組、變異組、轉錄組、表型組等不同層面整合了大豆相關數據集,實現了不同層次組學數據的交互查詢和聯合比較分析。
為更好服務于用戶,研究團隊開發了多個實用的“一站式”分析模塊,支撐實現GWAS分析、表達模式分析、單倍型分析、基因組坐標轉換、圖泛基因組可視化等。綜上,該數據庫具備多維組學數據間的深度關聯性、用戶的高度可交互性以及分析場景的高覆蓋性,預期能為大豆遺傳學及育種研究提供基礎數據支撐和全新的觀察視角。
中科院遺傳發育所田志喜研究員,中科院北京基因組所(國家生物信息中心)章張研究員、宋述慧研究員為該論文共同通訊作者,中科院遺傳發育所劉羽誠博士,中科院北京基因組所(國家生物信息中心)博士研究生張陽、劉曉楠,中科院遺傳發育所申妍婷副研究員為該論文共同第一作者。該研究得到了中科院先導項目、科技創新2030-重大項目、國家自然科學基金、國家重點研發計劃、博士后創新人才計劃等項目的資助。
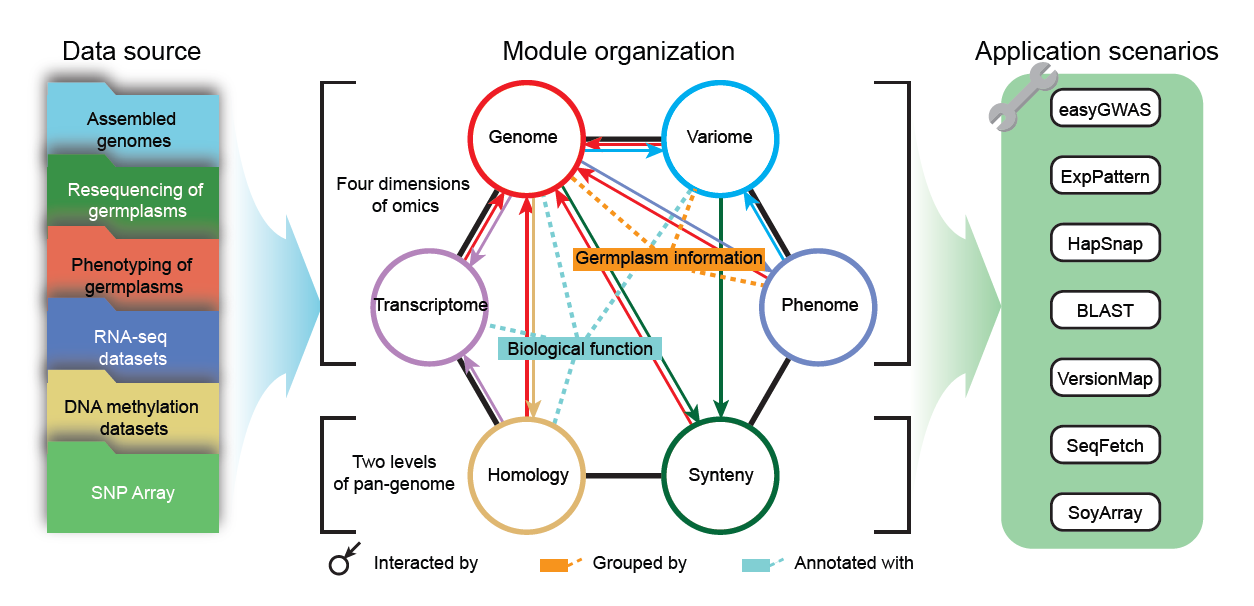
SoyOmics數據庫結構框架


